
数据结构
集合
集合继承体系
Collection接口: 单列集合,用来存储一个一个的对象
Map接口:双列集合,用来存储一-对(key - volue) 一对的数据
集合与数组区别
集合、数组都是对多个数据进行存储操作的结构,简称Java容器。
说明:此时的存储,主要指的是内存层面的存储,不涉及到持久化的存储(. txt,.jpg,.avi,数据库中)
数组
数组存储的特点
一旦初始化以后,其长度就确定了
数组一-旦定义好,其元素的类型也就确定了。我们也就只能操作指定类型的数据了。
比如: String[] arr;int[] arr1;object[] arr2;
数组存储的弊端:
一旦初始化以后, 其长度就不可修改。
数组中提供的方法非常限,对于添加、删除、插入数据等操作,非常不便,同时效率不高。
获取数组中实际元素的个数的需求,数组没有现成的属性或方法可用
数组存储数据的特点:有序、可重复。对于无序、不可重复的需求,不能满足。
集合
解决数组存储数据方面的弊端。
初始化集合
add
1 | List<String> languages = new ArrayList<>(); |
Arrays 工具类
1 | List<String> jdks = Arrays.asList("JDK6", "JDK8", "JDK10"); |
上面的 asList 是 Arrays 的静态方法,这里使用了静态导入。这种方式添加的是不可变的 List, 即不能添加、删除等操作
如果要可变,那就使用 ArrayList 再包装一下,如下面所示。
1 | List<String> numbers = new ArrayList<>(Arrays.asList("1", "2", "3")); |
集合通用方法
==向Collection接口的实现类的对象中添加数据obj时,要求obj所在类要 重写equals().==
存储有序的、可重复的数据
1 |
|
查找
contains 查重
contains(object obj)判断当前集合中是否包含obj 返回true/false
1 | arrayList.contains(123);//true |
containsAll 查重所有
contains(object obj)判断 形参集合中的所有元素 是否都存在于当前集合中
1 | // 2. containsAll(Collection coll1): 判断 形参集合中的所有元素 是否都存在于当前集合中 |
删除
remove 删除
remove(Object obj): 从当前集合中移除obj元素
1 | System.out.println(arrayList.remove(123));//移除成功返回true |
removeAll 删除所有
removeALL(Collection colL1):从当前集 合中移除arrayList1中所有的元素
1 | Collection arrayList1 = Arrays.asList(123,"Huiex"); |
交集
retainAll 交集
retainAll(Collection coll1):交集:获取当前集合和arrayList2集合的交集,并返回给当前集合
1 | Collection arrayList2 = Arrays.asList(123,"Huiex",456); |
比较
equals(0bject obj): 比较两个集合是否相等
原理是依次将集合中元素进行单个比较(contains)方法
主要有序比较,所以集合即便元素相同,但顺序不同仍 false
1 |
|
Collections工具类
Collections是一个操作Set、List 和Map等集合的工具类
1 | Collections中提供了一系列静态的方法对集合元素进行排序、查询和修改等操作, |
顺序
- reverse(List):反转List 中元素的顺序
- shuffle(List): 对List集合元素进行随机排序
- sort(List):根据元素的自然顺序对指定|List集合元素按升序排序
- sort(List,Comparator): 根据指定的Comparator产生的顺序对List集合元素进行排序
返回
- swap(List, int, int): 将指定list集合中的i处元素和j处元素进行交换
- Object max(Collection): 根据元素的自然顺序,返回给定集合中的最大元素
- Object max(Collection, Comparator): 根据Comparator指定的顺序,返回给定集合中的最大元素
- Object min(Collection)
- Object min(Collection,Comparator)
- int frequency(Collection, Object): 返回指定集合中指定元素的出现次数
复制替换
- void copy(L ist dest,List src): 将src中的内容复制到dest中
- boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换List对象的所有旧值
1 | public class CollectionsTest { |
集合和数组转化
将集合转化为数组
调用Arrays.类的静态方法toArray 该方法只支持包装类,无法转化为int型
1 | // 使用泛型,无需显式类型转换 |
1 | String[] arr = set.toArray(new String[set.size()]); |
使用循环
1 | int[] d = new int[list.size()]; |
使用流
1 | int[] arr1 = list.stream().mapToInt(i -> i).toArray(); |
.stream() 将list转化为流,.mapToInt(i -> i) mapToObj可以为流中的每个元素返回一个Int流 这里是将Integer对象流转化为int流.toArray() 将流中的元素返回到一个数组中去
将数组转化为集合
asList 调用Arrays.类的静态方法asList()
1 | ArrayList<String> arrayList = new ArrayList<String>(Arrays.asList(arrays)); |
1 | HashSet<Character> list1 = new HashSet<Character>(Arrays.asList('a', 'e', 'i', 'o', 'u', 'A', 'E', 'I', 'O', 'U')); |
1 | List<String> list = Arrays.asList(new String[]{"aa", "bb"}); |
使用Collections.addAll()
1 | List<String> list2 = new ArrayList<String>(arrays.length); |
迭代器
迭代器模式的定义为:提供一种方法访问一个容器(container)对象中各个元
素,而又不需暴露该对象的内部细节。迭代器模式,就是为容器而生。
Iterator
Iterator对象称为迭代器(设计模式的一种),主要用于遍历Collection集合中的元素。
1 | Collection arrayList1 = new ArrayList(); |
Iterator iterator = arrayList1.iterator();
Ilterator仅用于遍历集合,Iterator本身并不提供承装对象的能力。如果需要创建Iterator对象,则必须有一个被迭代的集合。
集合对象每次调用iterator()方法都得到一个全新的迭代器对象,默认游标都在集合的第一个元素之前。
iterator.hasNext()
判断是否还有下一 个元素
iterator.next()
指针下移 并将下移以后集合位置上的元素返回
remove
删除集合中的元素
1 | //一边遍历一边删除集合中的元素,遍历结果不含要删除的元素 |
和之前remove不同在于 上面是明确知道要删除的元素,而这个是不想在遍历出来的结果出现某个元素,起到过滤作用
List
存储
存储有序的、可重复的数据。 集合中的每个元素都有其对应的顺序索引。可以当做“动态”数组 列表
List容器中的元素都对应一个整数型的序号记载其在容器中的位置,可以根据序号存取容器中的元素。
子类
List的子类 ArrayList LinkedList Vector
ArrayList LinkedList Vector 三者的异同
1 | ArrayList 作为ist接口的主要实现类;线程不安全的,效率高;底层使用bject[]存储 |
1 | LinkedList 对于频繁的插入、删除操作,使用此类效率比Arpayttst高; 底层使用双向链表度储 |
1 | Vector 作为List接口的古老实现类:线程安全的,效率低;底层使用object[]存储 |
ArrayList
方法
1 | ArrayList list = new ArrayList(); |
添加
void add(int index, Object ele):在index位置插入ele元素
1 | list.add(2,"abc");//在list中的第二个索引位置添加元素 |
boolean addALl(int index, Collection eles): M从index位置开始将eLes中的所有元素添加
1 | List<Integer> list1 = Arrays.asList(1, 2, 3); |
删除
int indexOf(object obj): 返回obj在当前 集合 中末次出现的位置(索引)(查不到返回-1)
1 | System.out.println(list.indexOf(123));//0 |
Object remove(int index):移除指定index位置的元素,并返回此元素
1 | Object o = list.remove(0); |
Object remove(object obj) 移除指定的元素,并返回bool
1 | list.remove("Huiex"); |
区分List中remove(int index) 和remove(Object obj)
1 | public void test2(){ |
结果为[1]
list.remove(2);传的参为int 2,所以删掉 3
list.remove(new Integer(2));传的参为对象 2,所以删掉 2
修改
Object set(int index, object ele):设置指定index位置的元素为ele
1 | list.set(1,"Huiex"); |
查找
object get(int index):获取指定index位置的元素
1 | System.out.println(list.get(0));//123 |
int LastIndexOf(object obj):返回obj在当前集合中末次出现的位置
1 | System.out.println(list.lastIndexOf(123));//5 |
List sublist(int fromIndex, int toIndex):返回一个新list 从fromIndex到toIndex位置的左闭右开区
1 | List list2 = list.subList(1, 5); |
Vector
Vector 可实现自动增长的对象数组。
java.util.vector提供了向量类(Vector)以实现类似动态数组的功能
同样可以使用ArrayList中的API
作用
对于预先不知或者不愿预先定义数组大小,并且需要频繁地进行查找,插入,删除工作的情况,可以考虑使用向量类。
构造方法
1 | public vector() 第一种构造方法创建一个默认的向量,默认大小为 10: |
initialcapacity设定向量对象的容量(即向量对象可存储数据的大小),当真正存放的数据个数超过容量时。系统会扩充向量对象存储容量。
参数capacityincrement给定了每次扩充的扩充值。当capacityincrement为0的时候,则每次扩充一倍,利用这个功能可以优化存储。
方法
添加
1 | public final synchronized void addElement(Object obj) |
1 | public final synchronized void setElementAt(Object obj,int index) |
删除
1 | public final synchronized void removeElement(Object obj) |
1 | public final synchronized void removeAllElement(); |
1 | public fianl synchronized void removeElementAt(int index) |
查找
1 | public final int indexOf(Object obj) |
1 | public final synchronized int indexOf(Object obj,int index) |
1 | public final synchornized firstElement() |
1 | public final synchornized Object lastElement() |
其他
1 | public final int size(); |
1 | public final synchronized void setSize(int newsize); |
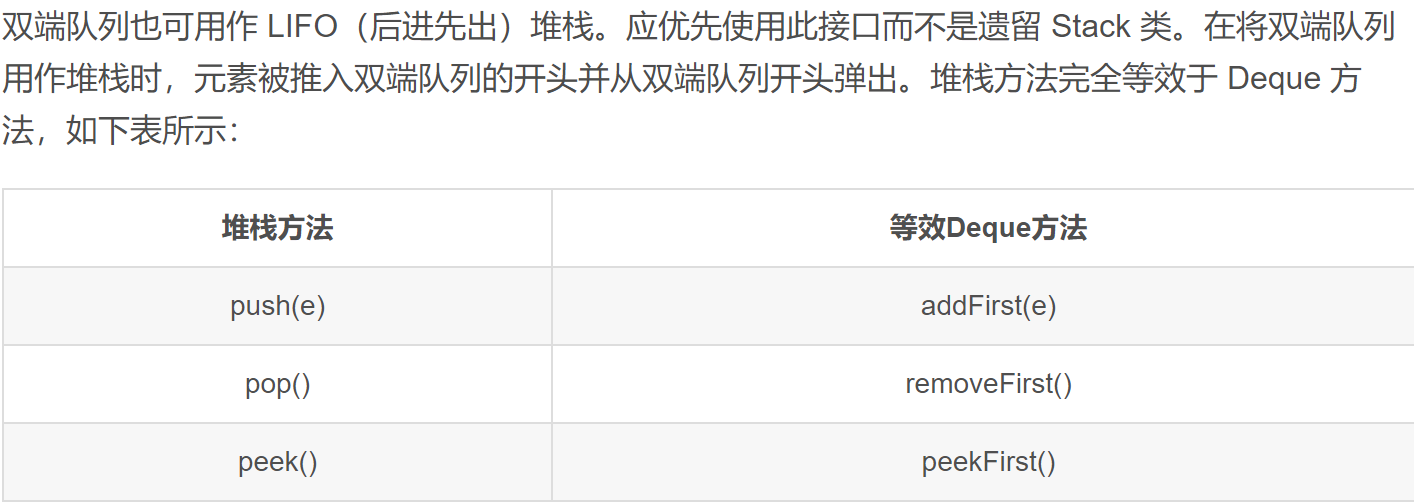
Stack
Stack类继承自Vector类
由于Stack和继承于Vector,因此它也包含Vector中的全部API。
创建
Stack是类,可以直接创建
1 | Stack<Integer> stack = new Stack<>(); |
方法
1 | E push(E item) 压入栈顶 |
Set
定义
存储无序的、不可重复的数据 就是高中讲的集合 集合
HashSet、LinkedHashSet、 TreeSet
Set接口:存储==无序的、不可重复的数据==
以HashSet为例说明:
无序性:不等于随机性。存储的数据在底层数组中并非按照数组索引的顺序添加,而是根据数据的哈希值
哈希表边存放的是哈希值。HashSet 存储元素的顺序并不是按照存入时的顺序(和 List 显然不同) 而是按照哈希值来存的所以取数据也是按照哈希值取得
不可重复性:保证添加的元素按照equals()判断时,不能返回true.即:相同的元素只能添加一 个
HashSet、LinkedHashSet、TreeSet三者的异同:
HashSet: 作为Set接口的主要实现类;线程不安全的;可以存储nuLL值
LinkedHashSet: 作为HashSet的子类; 遍历其内部数据时,可以按照添加的顺序遍历,对于频繁的遍历操作,
L inkedHashSet效率高FHashSet.
TreeSet: 可以按照添加对象的指定属性,进行排序
Set的方法 和 list一致
Set添加元素原理
添加元素的过程:以HashSet 为例:
1 | 我们向HashSet中添加元素a,首先调用元素a所在类的hashCode()方法,计算元素a的哈希值, |
==向Set中添加的数据,其所在的类一定要重写hashCode()和equals()==
方法
添加
1 | add() //将指定的元素添加到集合中 |
删除
1 | boolean remove(Object o); //从集合中移除指定的元素 |
长度
1 | int size(); |
判断
1 | boolean isEmpty(); |
1 | hashCode() -返回哈希码值(集合中元素的地址) |
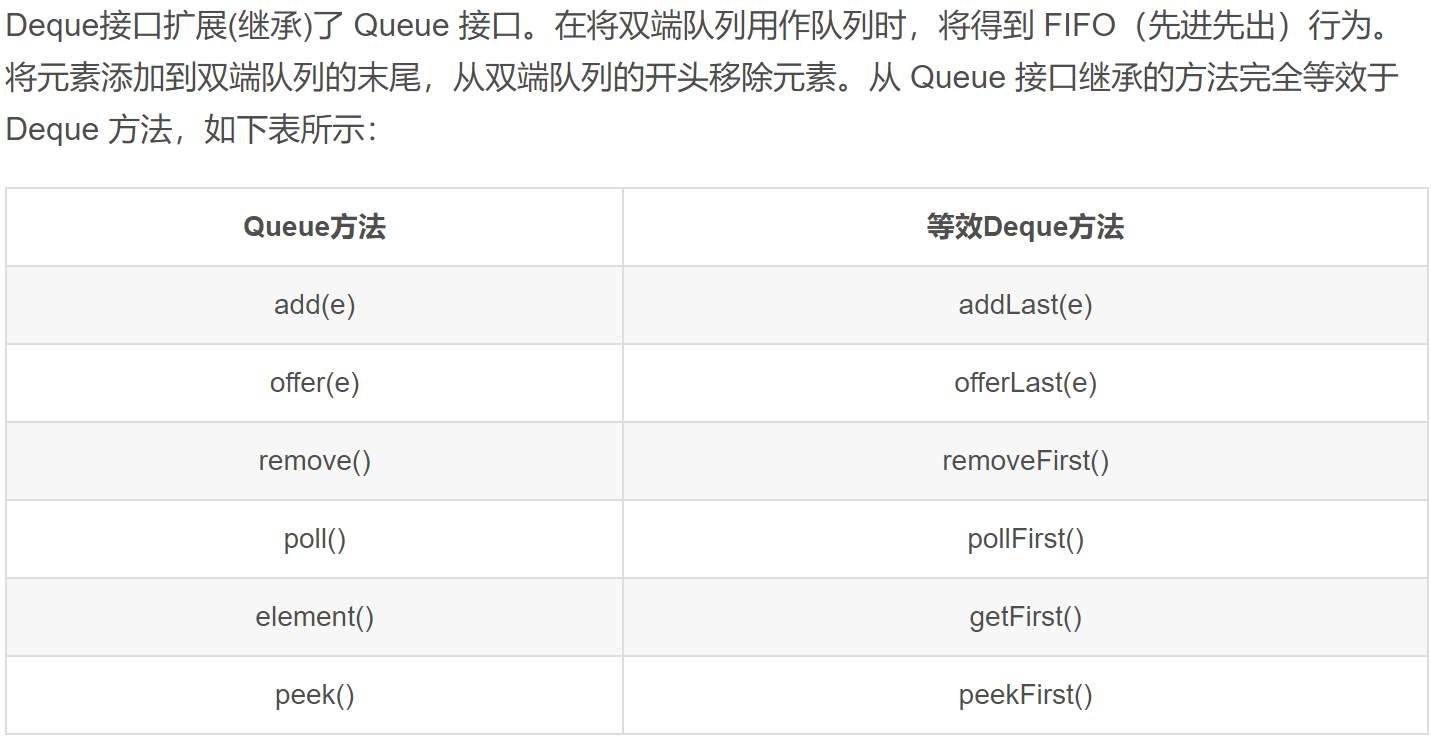
Queue
创建
1 | Queue<String,String> queue = new LinkedList<>(); |
==因为queue是接口,不能new 接口,应该new接口实现类==
下面有一大堆实现queue的类,选一个就行,针对队列的,你可以选LinkedBlockingQueue, AbstrctQueue, ArrayDeque
方法
添加
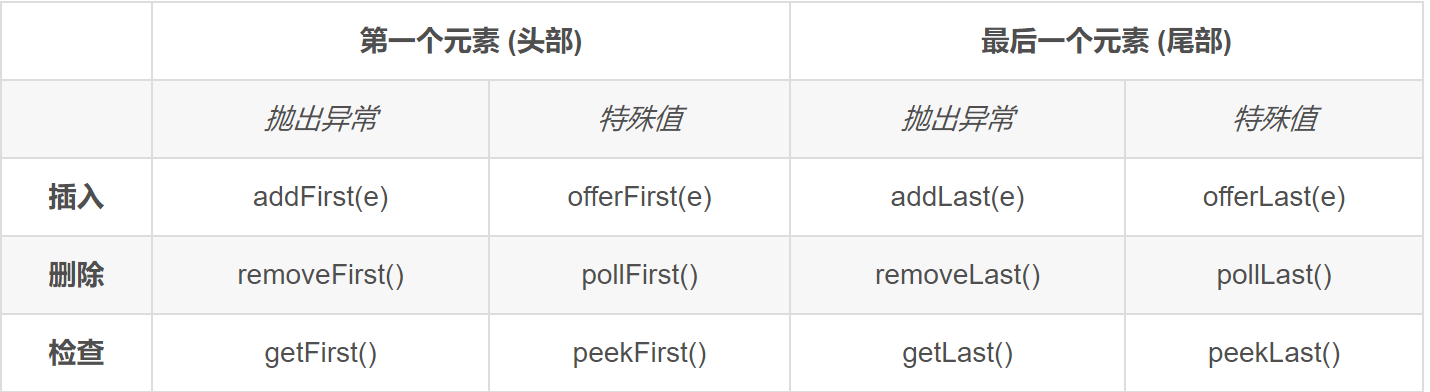
压入元素(添加):add()、offer()
相同:未超出容量,从队尾压入元素,返回压入的那个元素。
区别:在超出容量时,add()方法会对抛出异常,offer()返回false
删除
弹出元素(删除):remove()、poll()
相同:容量大于0的时候,删除并返回队头被删除的那个元素。
区别:在容量为0的时候,remove()会抛出异常,poll()返回false
不删除
获取队头元素(不删除):element()、peek()
相同:容量大于0的时候,都返回队头元素。但是不删除。
区别:容量为0的时候,element()会抛出异常,peek()返回null。
Deque
双端队列 Deque是一个线性collection,支持在两端插入和移除元素
有三种用途 双端队列 普通队列 栈
1 | Deque deque = new LinkedList(); |
双端队列
队列
栈
PriorityQueue堆
优先队列
排序的时间复杂度是 N
创建
默认为小根堆,实现大根堆需要重写一下比较器。
1 | PriorityQueue<Integer> priorityQueue = new PriorityQueue<>((Integer v1,Integer v2) -> v2 - v1); |
方法
添加
向优先队列中插入元素 add(E e) offer(E e)
删除
poll()
删除元素:删除堆顶元素——队列为空的时候返回null
remove()
删除堆顶元素——队列为空的时候抛出异常NoSuchElementException()
不删除
peek()
获取队列顶部元素——仅仅获取,没有删除
element()
获取堆顶元素——队列为空抛异常NoSuchElementException()
Map
Map接口
双列集合,用来存储一-对(key - volue) 一对的数据
HashMap、 L inkedHashMap、 TreeMap、 Hashtable、Properties
Map:双列数据,存储key-value对的数据
HashMap、TreeMap、Hashtable三者的异同:
1 | - HashMap: |
map存储原理图
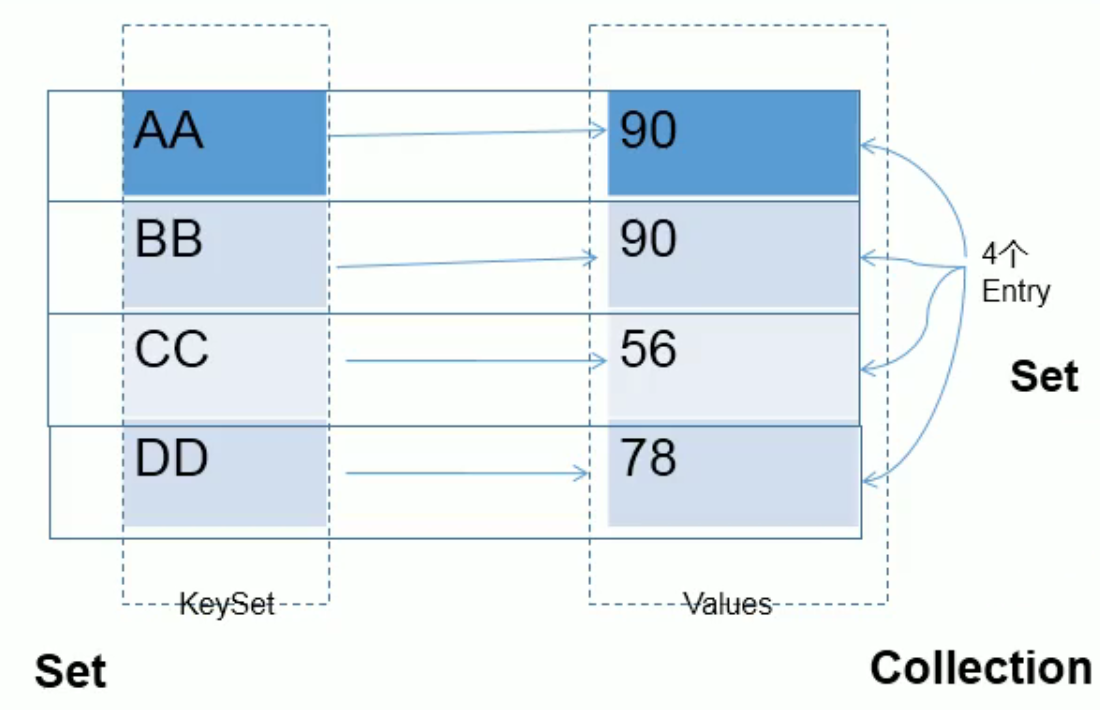
1 | Map中的key:无序的、不可重复的,使用Set存储所有的key |
1 | Map中的value:无序的、可重复的,使用Collection存储所有的vaLue |
1 | 一个键值对: key-value 构成了一个Entry对象。 |
HashMap底层原理
以jdk7为例说明
HashMap map = new HashMap():
在实例化以后,底层创建了长度是16的一维数组Entry[] table
map. put(key1, value1):
首先,调用key1所在类的hashCode()计算key1哈希值,此哈希值经过某种算法计算以后,得到在Entry数组中的存放位置。
如果此位置_上的数据为空,此时的key1-value1 添加成功。—- 情况1
如果此位置上的数据不为空,(意昧着此位置上存在-一个或多个数据(以链表形式存在)),比较key1和已经存在的-一个或多个数据的哈希值:
如果key1的哈希值与已经存在的数据的哈希值都不相同,此时key1-value1 添加成功。—- 情况2
如果key1的哈希值和已经存在的某一个数 据(key2-value2)的哈希值相同,继续比较:调用key1 所在类的equals(key2)
如果equals()返回faLse:此时key1-value1添加成功。—-情况3
如果equaLs()返回true:使用value1替换value2。
补充:关于情况2和情况3:此时key1-value1 和原来的数据以链表的方式存储。
在不断的添加过程中,会涉及到扩容问题,默认的扩容方式:扩容为原来容量的2倍,并将原有的数据复制过来。|
jdk8
相较于jdk7在底层实现方面的不同:
- new HashMap():底层没有创建一 个长度为16的数组
- jdk 8底层的数组是: Node[],而非Entry[] .
- 首次调用put()方法时,底层创建长度为16的数组
- jdk7底层结构只有:数组+链表。jdk8中底层结构:数组+链表+红黑树。
当数组的某- -个索引位置上的元素以链表形式存在的数据个数> 8且当前数组的长度> 64时,
此时此索引位置上的所有数据改为使用红黑树存储。
方法
添加/修改
1 | put(key,value) |
删除
1 | Object remove(key) |
1 | clear() //清空map中的键值对 |
查询
1 | Object get(Object key) //获取指定key对应的value |
1 | Object getOrDefault(Object key, Object o); //获取指定key的value,如果没有就默认返回o |
1 | boolean containsKey(Object key) //是否包含指定的key |
1 | boolean containsValue(Object value) //是否包含指定的value |
1 | int size() //返回map中key-value对的个数 |
1 | hoolean isEmpty() //判断当前map是否为空 |
1 | boolean eqyals(object obj) //判断当前map和参数对象obj是否相等 |
遍历
Set keySet(): 返回所有key构成的Set集合
1 | HashMap map = new HashMap(); |
Collection values(): 返回所有value构成的Collection集合
1 | //遍历所有value:value() |
方法一
Set entrySet(): 返回所有key-value对构成的Set集合
1 | //遍历所有的key-value |
方法二
返回所有key构成的Set集合,再用key查询 value;
1 | Set keySet = map.keySet(); |
根据键、值排序
以Key进行排序
我们可以声明一个TreeMap对象
然后往map中添加元素,通过输出结果,可以发现map里面的元素都是排好序的
1 | Map<Integer, Person> map = new TreeMap<Integer, Person>() |
想自定义的话 就在构造器的参数里面重新Comparator();
以value进行排序
先声明一个HashMap对象
将Map集合转换成List集合,最后借助Collections工具类进行排序
1 | Map<String, Integer> map = new HashMap<String, Integer>(); |
这样就实现了Map中的value按逆序排序,如果需要升序排的话,只需要修改o2.getValue()-o1.getValue()为o1.getValue()-o2.getValue()即可。
String
String:字符串,使用一对“ ”引号起来表示。
String实现了Serializable接口:表示字符串是支持序列化的。
实现了Comparable接口:表示String 可以比较大小
不能不初始化字符串
1 | String str; |
str是对象,你这是啥,空间都没有开辟
不可变性
==String声明为final的,不可被继承== String内部定义了final char[] value用于存储字符串数据
代表不可变的字符序列。简称:不可变性
体现: 1.当对字符串重新赋值时,需要重写指定内存区域赋值,不能使用原有的value进行赋值。
2.当对现有的字符串进行连接操作时,也需要重新指定内存区域赋值,不能使用原有的value进行赋值。
3.当调用String的replace()方法修改字符或字符事时,也需要重新指定内存区域赋值
1 | String s1 = "abc"; |
String的实例化
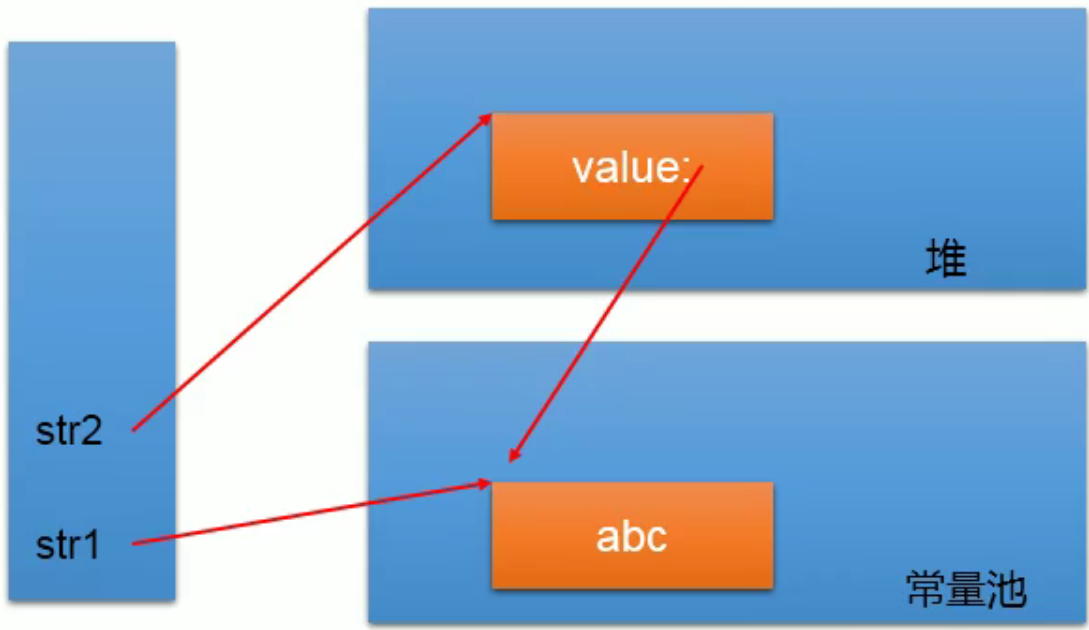
通过字面量定义的方式
通过字面量的方式String s1 = “abc”(区别于new)给一个字符串赋值,此时的字符串值声明在字符串常量池中
字符串常量池中是不会存储相同内容的字符串的
通过new +构造器的方式
通过new +构造器的方式 String s2 = new String(“abc”) 此时的s2保存的地址值,是数据在堆空间中开辟空间以后对应的地址值。
常量与常量的拼接 “abc” +“def” 结果在常量池。且常量池中不会存在相同内容的常量
变量与常量 s1 + “abc”的拼接结果只在堆中
如果拼接的结果调用intern()方法,返回值就在常量池中
相关题
方法将 一个字符串 还有一个字符数组 改变,主函数输出是否会受到影响
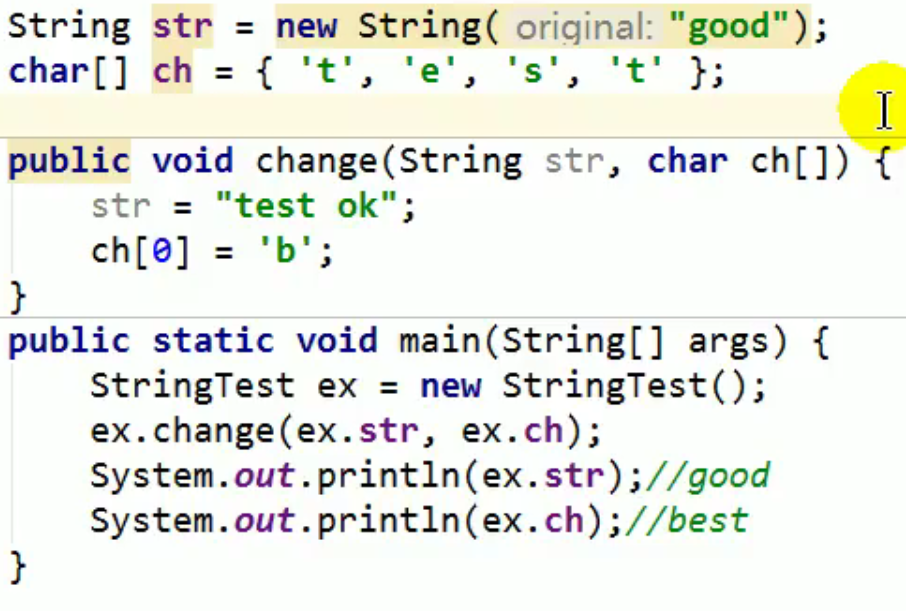
因为 str为引用数据类型,传递给形参的是地址
而char []中的char[0]是char为基本数据类型,传递的是真实存储的数据值,能够被改变
String类方法
大小写
1 | String toLowerCase():使用默认语言环境,将String中的所有字符转换为小写,不改变原字符串 |
去除两端
1 | String trim():返回字符串的副本,忽略前导空白和尾部空白 |
比较
1 | boolean equals(Object obj):比较字符串的内容是否相同 |
拼接
1 | String concat(String str):将指定字符串连接到此字符串的结尾。等价于用“+” |
截取
1 | String substring(int beginIndex):返回一个新的字符串,它是此字符串的从beginIndex开始截取到最后的一个子字符串。 |
判断
1 | boolean endsWith(String suffix):测试此字符串是否以指定的后缀结束 |
查找
1 | boolean isEmpty():判断是否是空字符串:return value.length==0 |
替换
1 | String replace(char oldChar, char newChar):返回一个新的字符串,它是通过用 newChar 替换此字符串中出现的所有 oldChar 得到的。 |
1 | Java删除字符串中的指定字符 |
切片
1 | String[] split(String regex):根据给定正则表达式的匹配拆分此字符串。 |
翻转字符串
1 | String reverse = new StringBuffer(string).reverse().toString(); |
类型转换
int <==> String
String –> 基本数据类型、包装类
调用包装类的静态方法:parseXxx(str)
1 | String str1 = "123"; |
基本数据类型、包装类 –> String
调用String重载的valueOf(xxx) 或者 拼接“ ”
1 | String str2 = String.valueOf(num); //"123 |
char[] <==> String
String –> char[]
调用String的toCharArray()
1 | String str1 = "abc"; |
char[] –> String
调用String的构造器
1 | char[] arr = new char[]{'h','e','l','l','o'}; |
char <==> String
char –> String
1 | String s = String.valueOf('c'); //效率最高的方法 |
String –> char
1 | char c = str.charAt(i);//将字符串指点索引下的字符转换为char |
StringBuffer
异同
String、StringBuffer、StringBuilder三者的异同?
- String:不可变的字符序列;底层使用char[]存储
- StringBuffer:可变的字符序列;线程安全的,效率低;底层使用char[]存储
- StringBuilder:可变的字符序列;jdk5.0新增的,线程不安全的,效率高;底层使用char[]存储
原理
StringBuffe和StringBuilder 默认初始化会构建一个长度为16的数组,
1 | StringBuffer sb1 = new StringBuffer(); |
1 | StringBuffer sb2 = new StringBuffer("abc"); |
如果要添加的数据底层数组盛不下了,那就需要扩容底层的数组。
默认情况下,扩容为原来容量的2倍 + 2,同时将原有数组中的元素复制到新的数组中ofCopy()方法
初始化
使用构造器,手动定义新建的数组长度capacity,否则默认长度为16
1 | StringBuffer sb1 = new StringBuffer(int capacity) |
常用方法
增
1 | StringBuffer append(String xxx):提供了很多的append()方法,用于进行字符串拼接 |
删
1 | StringBuffer delete(int start,int end):删除指定位置的内容 |
改
1 | StringBuffer replace(int start, int end, String str):把[start,end)位置替换为str |
查
1 | int indexOf(String str) str在字符串中的位置 没有返回-1 |
1 | StringBuffer reverse() :把当前字符序列逆转 |
长度
1 | int length(): 字符串长度 |
String之间的转化
String —> StringBuffer
通过构造方法
1 | StringBuffer sb = new StringBuffer(String s); |
通过append()方法
1 | String s = "abc"; |
StringBuffer —> String
通过构造方法
1 | StringBuffer sb = new StringBuffer("abc"); |
通过toString()方法
1 | StringBuffer sb = new StringBuffer("abc"); |
Arrays
包:import java.util.Arrays
Arrays工具类都是静态的
网址:Java Arrays工具类 (biancheng.net)
比较
1 | boolean equals(int[] a,int[] b) 判断两个数组是否相等(元素逐个比较) |
输出
1 | String toString(int[] a) 输出数组信息 |
转换
1 | String toString(type[] a) |
添加
1 | void fill(int[] a,int val) 将指定值填充到数组之中 一般用于初始化数组 |
排序
1 | void sort(int[] a) 对数组进行排序。(快速排序) 时间复杂度为 nlogn |
查找
1 | int binarySearch(int[] a,int key) 对排序后的数组进行二分法检索指定的值,如果查找到,返回索引,如果没有,返回负数 |
复制
1 | type[] copyOf(type[] original, int length) |
切片
1 | copyOfRange(被切片的数组, begin_index, end_index)//左闭右开 |
Math类
java.lang.Math提供了一系列静态方法用于科学计算。其方法的参数和返回值类型一般为double型。
1 | abs 绝对值--------------------<< |
基本数据类型
int
int是4个字节,32位
2进制 10位数 2147483648 - 2147483647
long
2进制 19位数 9223372036854775807L(long型要加 L )- 9223372036854775808L
1 | Java基本类型包装类: |
Integer
Java中的Integer - 一只水饺 - 博客园 (cnblogs.com)
常量
最大的Int为: Integer.MAX_VALUE
最小的Int为: Integer.MIN_VALUE
构造方法
Integer(int number)该方法以一个int型变量作为参数来获取Integer对象。
1 | Intrger number = new Integer(7); |
Integer和int之间的转换
int到Integer:
int a=3;
Integer A=new Integer(a);
或:
Integer A=Integer.valueOf(a);
Integer到int:
Integer A=new Integer(5);
int a=A.intValue();
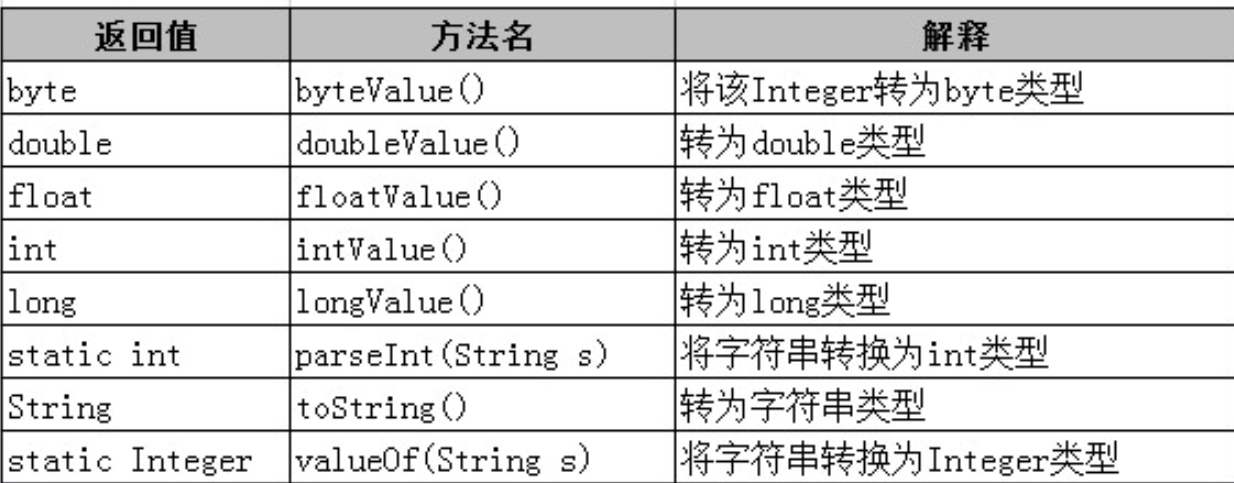
常用方法
进制转换
Integer类的toString()方法,可将Integer对象转换为十进制字符串表示。toBinaryString()、toHexString()和toOctalString()方法分别将值转换成二进制、十六进制和八进制字符串
1 | public class Charac { // 创建类Charac |
char
char –> int
1 | char c = '2'; |
int –> char
1 | int num =1; |
BigInteger
Java.math.BigInteger.gcd()方法实例
java.math.BigInteger.gcd(BigInteger val) 返回一个BigInteger,其值的最大公约数:abs(this) 和 abs(val)。它返回 0 如果 this==0 && val==0.
Java比较器
Java实现对象排序的方式有两种
- 自然排序:
java.lang.Comparable - 定制排序:
java.util.Comparator
作用
Java中的对象,正常情况下,只能进行比较:==或 != 。不能使用 >或<的
如果对多个对象进行排序,就可以使用使用两个接口中的任何一个:Comparable或 Comparator
Comparable自然排序
像String、包装类等实现了Comparable接口,重写了compareTo(obj)方法,给出了比较两个对象大小的方式。
代码默认调用(自然)
例如:
String[] arr = new String[]{“AA”,”CC”,”KK”,”MM”,”GG”,”JJ”,”DD”};
String类就继承了Comparable类,重写了里面的compareTo(obj)方法,通过比较字符的大小,根据重写compareTo(obj)进行比较
1 | 重写compareTo(obj)的规则: |
自定义类实现自然排序
如果像比较自定义的对象,就需要在该对象类中重写compare(Object o1,Object o2)方法
1 | 当元素的类型没有实现java.lang.Comparable接口而又不方便修改代码, |
使用Comparable实现定制排序
自己手动定义排序,需要在类中
1 | public class CompareTest { |
s
1 | /** |
使用Comparator实现定制排序
有些方法里面含义Comparator参数,就可以之间在参数里面写,(匿名类)规定排序方式
1 | public void test3(){ |
compareTo()
1 | public int compareTo( NumberSubClass referenceName ) |
compareTo() 方法用于将 Number 对象与方法的参数进行比较。可用于比较 Byte, Long, Integer等。该方法用于两个相同数据类型的比较,两个不同类型的数据不能用此方法来比较。
返回值
- 如果指定的数与参数相等返回0。
- 如果指定的数小于参数返回 -1。
- 如果指定的数大于参数返回 1。
比较方法
(1) 字符串与对象进行比较
(2) 按字典顺序比较两个字符串
先比较对应字符的大小(ASCII码顺序),如果第一个字符和参数的第一个字符不等,结束比较,返回他们之间的差值,如果第一个字符和参数的第一个字符相等,则以第二个字符和参数的第二个字符做比较,以此类推,直至得到最终结果或者其中一个参数结束。